社会学方法
调查实验法在社会学中的应用 方法论评述
内容提要: 调查实验法是近年来兴起的一种研究方法。它结合了调查和实验方法两者的优势,从而能够在保证样本代表性的基础上进行准确的因果推断。虽然这一方法有着广阔的应用前景,但它在国内社会学界还未受到充分关注。本文旨在介绍调查实验法的原理和优势,然后通过一个案例阐释此方法的操作流程,以及它在社会学研究中的应用场景,最后讨论调查实验法的局限和前景。
关键词:调查实验法;因果推断;定量研究;社会研究方法
作者简介:王森浒,新加坡国立大学社会学系;李子信,斯坦福大学博士候选人;陈云松,南京大学社会学院;龚顺,中国社会科学院社会学研究所
一、导言:社会学量化研究中的效度取舍
因果推断是社会科学量化研究的终极目标(陈云松、范晓光,2010;胡安宁,2012)。长久以来,社会学量化研究主要使用基于大规模代表性调查的观测数据(范晓光,2020)。然而,在反事实框架(counterfactual framework)下使用观测数据直接推测因果关系面临着内生性(endogeneity)的问题,即如果存在一个无法观测的干扰变量同时影响自变量和因变量,那么得出的因果关系就会存在偏差(Gangl,2010)。虽然之前的研究提出了一系列解决内生性问题的方法,比如工具变量、倾向值匹配、大数据和机器学习等(陈云松, 2012;胡安宁,2012;龚为纲、朱萌,2018),但是这些方法在因果推断方面都存在一定程度的缺陷(陈云松、范晓光,2010)。在众多研究方法中,实验法一直被认为是解决内生性问题和进行因果推断的黄金法则。因为实验可以通过随机化(randomization)确保因果关系的真实性,所以拥有很高的内部效度(Duflo et al., 2007)。然而,实验方法在社会学中的运用还非常有限。其中一个重要的原因是实验(特别是实验室实验)通常被认为缺乏外部效度,得出的研究结果缺乏代表性和推广性,无法运用到更广泛的场景中(方文, 1995)。比如,很多实验使用小规模的非代表性样本并在实验室中开展,所以最后的实验结果很难反映社会群体在真实世界中的行为和态度(Webster & Sell,2014)。由于社会学的很多议题关注社会整体层面的机制,并强调不同人群之间的异质性,尽管实验方法可以保证因果关系的真实性,但依然被认为不适用于社会学研究(彭玉生,2011)。
因此,长久以来社会学家在选择研究方法的时候一直面临着内部效度和外部效度之间的取舍问题:使用调查研究可以获得高外部效度但要牺牲一定的内部效度,使用实验研究可以获得高内部效度但要牺牲外部效度(方文,1995)。近年来,国际社会学界兴起了一个新的研究方法 —— 调查实验法(survey experiment)。 它结合了调查和实验方法两者的优势,从而可以兼顾研究的内部和外部效度,因此在社会学研究中的应用范围不断扩大(Mutz,2011;Auspurg & Hinz,2015;Wallander,2009)。此外,杰克森(Jack⁃ son)和考科思(Cox)2013 年发表在社会学权威研究综述期刊《社会学年鉴》(Annual Review of Sociology)上的论文也充分肯定了调查实验法的巨大价值,并强调了它对于社会学不同领域研究的重要意义(Jackson & Cox, 2013)。尽管调查实验法对社会学研究具有很大价值,但国内社会学界对于此方法的研究和运用尚处于起步阶段。
因此,本文旨在通过介绍调查实验这一新兴的研究方法把实验设计引入中国社会学的实证研究,从而丰富社会学量化研究,发展社会学理论,为构建中国特色社会主义社会学做出贡献。接下来,文章首先介绍调查实验的定义、分类和原理,然后通过将调查实验法与调查统计方法和其他实验法分别进行对比,凸显其在研究特定社会学问题上的优势。然后,文章通过分析一个具体的案例来详细介绍调查实验的设计及操作过程。接着,文章对调查实验在社会学研究中的意义和应用场景进行阐述,最后讨论了该方法的局限并对全文进行总结。
二、调查实验法的定义、分类和因果推断原理
(一) 定义与分类
调查实验指的是通过调查方法实施的以个人为对象的实验,也可以被通俗地理解为嵌入调查的实验(Mutz,2011)。因此,调查实验具有调查和实验的双重特征。从调查的角度来说,调查实验通常使用大规模的概率或非概率抽样,采用结构化的问卷,并通过实地面访、电话、邮寄或网络等形式收集数据。通过使用概率抽样或者加权非概率抽样,调查实验可以收集到具有代表性的样本,从而保证研究的推广性以及外部效度(Schaeffer & Presser, 2003)。从实验的角度来说,调查实验允许研究者操纵处理变量,即核心自变量,并且可以对样本进行随机化分组,从而保证了因果推断的准确性以及内部效度(Duflo et al., 2007)。
调查实验根据其研究问题可以分为两种类型。第一, 期的调查实验的主要目的在于提升社会调查和测量方法精度以及避免社会期许误差(social desirability bias)的影响。比如,对于一些敏感问题比如性取向、家庭暴力和种族歧视,受访者倾向于在调查中做出符合社会期望的回答,而非真实的回答。这类调查实验包括列举实验(list experiment)、随机应答(randomized response)等随机实验。它们通过随机化提问的方式保护受访人的隐私,从而得到他们真实的回答。第二,近年来越来越多的调查实验通过创造随机的虚拟情境(vignette)来进行因果推断。这类调查实验也被称为情景实验(vignette experiment),这是本文的重点。
情景实验又可以分为单因素和多因素的设计。单因素设计只包含一个实验变量,多因素设计又名析因设计(factorial design),可以包含多个实验变量。最 的单因素情景实验可以追溯到公共舆论研究中的“ 分选投票”(split-ballot)设计,即把受访者随机分成两组(实验组和控制组)并发放其他部分完全相同的问卷,但对其中一个问卷的问题进行实验处理(任莉颖, 2018)。比如,罗森把受访者随机分为两组来研究他们对一个虚拟家庭补助政策的态度(Rosen,1973)。实验组(experimental group/treatment group)的政策包含了总统支持这个政策的信息,而控制组(control group,或称对照组, comparison group)则没有这一消息。结果发现实验组中的受访者对政策的支持率更高,从而揭示了总统对于政策支持度的影响。单因素情景实验也可以从简单的两个情景拓展到多个情景,进而比较不同类型实验干预的处理效应(treatment effect)。
除了单因素设计,多因素设计或析因调查实验可以帮助我们对多个实验变量进行随机化,从而分析社会现象的多维构成和复杂决定因素(Snider⁃ man, 2018)。比如,人们对目前生活的满意程度取决于人们对生活多个维度的评价,比如工作收入的高低、家庭生活是否和谐、业余活动是否丰富等。假设一个人的生活包含五个维度,且每个维度包含两个层面,那么全析因设 计(full factorial design)会得出这五个维度排列组合的所有可能性,即32(2× 2×2×2×2=32)个不同生活情景。然后,我们将这些情景嵌入问卷,让每个受访者对这32 个情景或者它的随机样本进行满意度评分,从而可以了解人们对于不同生活方面的权衡和取舍。最 的析因调查实验可以追溯到罗西等对家庭地位评价的研究。他们通过选取三个变量:家庭角色、教育和职业地位创建了664 个虚拟家庭案例,然后将它们随机嵌入调查问卷,以考察人们对家庭地位不同侧面的评价(Rossi et al., 1974)。
近年来,随着互联网的普及和电脑辅助调查技术的发展,越来越多的调查实验由网络调查公司、社交媒体或众包平台(比如Qualtrics、领英、亚马逊 Mechanical Turk 等)协助收集数据,从而与大数据相结合(罗玮、罗教讲, 2015)。相比线下调查实验,线上调查实验有几大重要的优势(翁茜、李栋,2020)。第一,研究者可以通过互联网在短时间内获得大量的样本,并通过对这些样本进行加权一定程度上保证它的代表性。第二,复杂的析因调查实验设计可能包括几十甚至上百个虚拟情景,需要把这些情景放入不同问卷然后随机发放。这对于线下的问卷调查有很大操作难度,但是对于线上调查实验则非常简单。第三,线上调查实验可以获得准确性更高的数据。比如,研究者在获得用户授权后,可以在网络平台的协助下获得匿名受访者的历史行为记录和其他大数据信息,从而可以提高抽样的准确性和干预的随机性。然而,在线调查实验也面临着一些挑战,比如基于互联网使用者的潜在样本选择偏差以及和第三方网站运营者的协调问题(翁茜、李栋, 2020)。
(二) 因果推断原理
通过引入反事实框架,我们可以考察调查实验是如何进行因果推断的。根据奈曼-鲁宾因果模型(Neyman-Rubin causal model),反事实(coun terfactual outcomes)(也叫潜在结果,potential outcomes)指的是一件事情在相反情况下的状态(胡安宁, 2012)。比如,一组人在接种疫苗以后对某种疾病的感染率有所降低,那么这件事的反事实指的是,如果这些人没有接种疫苗,他们的感染率是怎么样的。模型的数学表达可以写成公式1。在等式的左边,E(δ) 指的是预期因果效应。在等式的右边,T 代表个体在实验组(1)还是控制组(0),Y1 代表实验组中因变量的取值,Y0 代表控制组中因变量的取值,π 代表实验组受访者的占比(见表1)。因此,等式右边主要包含了两个部分:实验组的因果效应和控制组的因果效应。所以总的预期因果效应 E(δ)就等于实验组和控制组的因果效应的加权平均数。
E(δ)= π[E(Y1|T = 1) - E(Y0|T = 1)] +(1 - π)[E(Y1|T = 0) - E(Y0|T = 0)] (式1)

然而,在现实中我们永远没有办法观察到反事实的情况,这也被称为 “因果推论的根本问题”(Holland, 1986)。以支持性的家庭政策对结婚意愿的影响这一家庭和人口研究领域的重要问题为例(Gong & Wang, 2021),家庭政策不可能在某一人群中同时实施和不实施。因此,我们需要用其他人群去“模拟”反事实的状态。对于实施了家庭政策人群的反事实状态,我们可以用未实施家庭政策的人群去“模拟”。相似的,对于未实施家庭政策的人群的反事实状态,我们可以用实施了家庭政策的人群去“模拟”。由于我们在现实中没有办法直接观察到反事实,所以我们在推测因果关系的过程中就不可避免地碰到“虚假相关”(spurious correlation)的问题。比如,即使在观测性数据中发现家庭政策和结婚意愿呈显著正相关,即实施家庭政策后,结婚意愿显著提高,也无法确定这种相关关系是因果关系。有一种可能是,这个相关关系的背后有一个共同的决定因素,即对经济形势的乐观预期。良好的财政预期可能会推动家庭政策的施行;同时积极的经济预期也可能减少结婚的负担。换言之,家庭政策的实施和结婚意愿之间本质上并没有关系,它们之间的虚假相关是由它们背后一个共同的机制即经济预期决定的。由于类似的混淆因素(confounder)难以枚举,在统计模型中加入有限的控制变量可能会遗漏一些混淆因素。综上所述,由于我们无法完全模拟反事实状态,所以用观测数据推测因果关系面临着巨大的挑战。
然而在实验中,随机分组可以确保我们能够成功“模拟”反事实状态。根据大数定理,随着实验组和控制组的样本量不断增大,随机分组可以有效地消除实验组和控制组中由个体造成的差异,使得这两个组在除了实验干预以外的其他特征上完全一致。因为在因果推断中随机实验可以满足非混淆假设(unconfoundedness assumption),它的数学表达式可以写成:
E(Y0 | T = 1) = E(Y0 | T = 0)
E(Y1 | T = 0) = E(Y1 | T = 1)
然后,我们将以上两个等式带入公式1 可以得出简化的因果模型公式2。至此,在随机实验中,因果效应可以简单表达成实验组和控制组在因变量上的差。
E(δ) = [E(Y1 | T = 1)-E(Y0 | T = 0)] (式2)
总结来说,调查实验法利用随机化消除实验组和控制组的系统性差异,从而解决了内生性问题并保证了因果推断的准确性。另外,实验数据对统计模型函数的假设较少,在很多情况下,普通最小二乘法或非参数分析即可完成因果推断,这不仅使得结果简单易懂,而且可以提高统计功效。
三、调查实验法作为新兴量化研究方法的优势
每种研究方法都有其独特的优势和适用范围。在这一节中,我们将通过比较调查实验法和其他量化研究方法(包括调查统计法和其他实验方法)向读者阐明调查实验法的适用情况,以及在这些情况下相比于其他方法的优势。值得注意的是,这些方法不是相互排斥的关系,而是在不同情景和领域下可以互补甚至结合,进而帮助我们对社会复杂现象进行全面了解。
(一)调查实验法与调查统计法的对比
基于观测数据的调查统计法是一种回溯性方法,主要适用于描述现有已经发生的行为和态度,以及不同行为或态度之间的相关关系(而非因果关系)。这是因为传统调查统计法在因果推断时需要依赖很多假设,但这些假设在现实当中通常很难完全满足(陈云松、范晓光,2010)。而调查实验法是一种前瞻性方法,主要通过操控实验状态和随机化分组来考察实验处理和结果变量之间的因果关系。由于这种实验设计被嵌入在调查问卷里,所以调查实验法主要适用于前瞻性地考察在不同实验状态下社会舆论、态度和价值观的变化,而无法研究已经发生的行为和态度。因此在社会舆论和态度的研究中,调查实验法比调查统计方法有着更高的内部效度和因果推断的准确性。接下来,我们将继续利用反事实框架来对比调查实验法和调查统计法。我们主要关注社会学研究中常见的三种调查统计方法:倾向值分析、固定效应模型和工具变量方法。我们认为,调查实验法相比调查统计法的优势在于更好地满足了非混淆假设。
倾向值分析和多元回归一样,本质上都是通过控制尽可能多的可观测混淆变量来满足非混淆假设的(胡安宁,2012)。在这里,混淆变量指的是有可能混淆自变量和因变量因果关系的变量,通常包括可以影响因变量或者可以同时影响因变量和核心自变量的变量。倾向值分析通过logistic 或probit 回归将所有的X总结为一个倾向值P,然后可以通过对倾向值匹配、分层或直接控制倾向值等方法来满足非混淆假设。通过控制可观测混淆变量的方法来满足非混淆假设有以下几大缺陷(胡安宁,2012)。第一,大量可观测变量有着不同程度的测量误差。比如很多回顾性问题往往因为人们的记忆偏差(re⁃ call bias)而产生很大的测量误差,相隔时间越久,这种误差变得越大(Schaef⁃ fer & Presser, 2003)。第二,并不是所有的特征都是可观测的。比如很多涉及人们隐私的问题由于伦理的限制无法测量(Gangl, 2010)。所以,在现实中多元回归和倾向值分析很难完全满足非混淆假设并进行有效的因果推断。
固定效应模型是通过控制所有个体非时变变量(time-constant variables)和可观测的时变变量(observable time-varying variables)来满足非混淆假设的(陈云松、范晓光, 2010)。由于排除所有组间变异并只关注组内变异,固定效应模型可以自动控制所有个体的非时变变量,同时也需要尽可能多地控制时变变量。然而,固定效应模型也不能完全满足非混淆假设并进行无偏差因果推断。这主要有两个原因。第一,虽然固定效应模型可以控制所有的非时变变量,但是它只能控制有限的可观测到的时变变量。一些遗漏的时变变量也有可能混淆最后得出的因果效应。第二,固定效应模型只关注组内变异,这就要求纳入模型的所有变量有足够大的组内变异。所以,固定效应模型无法研究一个只有很小或没有组内变异的自变量对于因变量的因果效应。基于这两个缺点,固定效应模型也无法完全满足非混淆假设从而进行无偏差因果推断。
工具变量方法通过寻找外部工具变量的方法来满足非混淆假设。工具变量需要具备以下特征(陈云松, 2012)。第一,工具变量应该是完全外生的。第二,工具变量只能通过影响核心自变量从而影响因变量。当找到满足条件的工具变量后,模型通过考察核心自变量和外生工具变量的共变部分对因变量的影响进行因果推断。虽然理论上工具变量方法有可能完全满足非混淆假设,但在现实中这种情况很少出现,主要有以下几个原因。第一,除了一些自然现象以外,完全随机且外生的工具变量比较少见。第二,即使找到完全外生的工具变量,也很难确保工具变量和核心自变量完全相关并且和因变量不相关。在很多情况下,工具变量和核心自变量的相关程度不高,造成弱工具变量问题。这个问题使得工具变量估计出的结果为局部而非全部因果效应,从而造成因果推断的偏差。
综上所述,这三种常用的调查统计方法在推断因果方面都依赖于比较强的假设,一旦这些假设在现实中无法满足就会导致因果推断的偏差。而调查实验法则可以利用随机化最大限度地满足非混淆假设,从而实现准确的因果推断。
(二)调查实验法与其他实验法的对比
除了调查实验,其他的实验设计还包括实验室实验和田野实验。实验室实验指的是在实验室中利用实验器材来研究被试(subject)在实验指令下做出的决策和行为,被试通常为大学生,他们知道研究的目的并获得一定的物质或非物质激励(Webster & Sell, 2014)。实验室实验主要关注个体层面差异,可以实现高度的实验控制,在心理学和经济学中得到广泛应用。然而,对于社会学家来说,关注“社会事实”,避免从个体特征机械地直接推断群体特征,是社会学自创立以来的旨趣(Durkheim, 1895)。所以,对社会情境和代表性样本的重视,也使得基于小样本和非概率抽样的实验法在社会学中的应用远不如在心理学等学科中广泛(Jackson & Cox, 2013; 谢宇, 2012)。
因此,在面对社会层面的问题时,调查实验法相比于实验室实验不仅同样可以解决因果推断这一根本问题,还在研究的外部效度上有两大优势(Mutz, 2011)。第一,调查实验可以针对一个国家或其他特定的人群进行概率抽样。在实验室实验中,被试的招募往往采取的是任意抽样,这就使得被试的社会人口学构成较为同质化。虽然理论上实验室实验也可以先对全国人口进行概率抽样,然后再邀请他们来实验室进行实验,但相比于在线填写问卷,参与线下实验的时间和交通成本较高,进而会导致较低的接受率和样本偏差。因此,在实践中,医学等学科普遍开展的临床试验亦鲜少采用概率抽样。第二,调查实验相比于实验室实验,可以较低的时间和经济成本收集较大的样本(翁茜、李栋, 2020)。实验室实验一般在每个分组仅收集数十个至一两百个样本,而调查实验则常常可以收集上万个样本(Auspurg et al., 2017)。较大的样本量使得根据社会人口学特征进行亚组的异质性分析(subgroup or heterogeneity analysis),进而揭示不同社会群体之间的差异性成为可能,为深化和细化社会学理论奠定了实证基础。尤其是近年来,我国社会学家开展了一系列有全国代表性的社会调查,已经有了较完备的抽样方法。调查实验可以便捷地嵌入其中,节约了重新招募被试的成本。值得注意的是,并非所有调查实验都采取了概率抽样方法。即使是未采取概率抽样的调查实验,也可以借助电脑向广泛的受访者大规模地发送调查问卷然后进行加权,增加样本的代表性和外部效度(Mutz, 2011)。
田野实验指的是在真实的场景中对被试进行实验,被试通常包含多样的人群并且不知道自己处于研究者的观察下(Gerber & Green, 2012)。因为实验场景的真实性和推测因果关系的准确性,田野实验同样具有很高的外部效度并在发展经济学等领域广泛运用(Duflo et al., 2007)。然而,调查实验可以在一定程度上弥补田野实验的不足或与田野实验结合,从而得出更为严谨的结论。比如,在样本量和代表性上,田野实验往往需要大量的时间、经济成本和执行团队的高度配合,也面临着更多被试系统性退出即实验耗损(attrition)的挑战(翁茜、李栋, 2020)。相比而言,调查实验通过网络可以很低的成本获得大量样本,且更容易获得被试的社会人口学数据,从而保证了被试在各实验组之间多维度的均衡。所以,调查实验既可以作为田野实验的前导实验,也可以用来检测在特定地区和人群中开展的田野实验的结论的普适性(Gerber & Green, 2012)。
表2 总结了各种常用的社会学定量方法在内部效度和外部效度方面的优劣势,进而展现了调查实验法的独特优势。值得强调的是,每种研究方法都有其适合回答的问题,并不存在一种在所有情况下都具有优势的研究方法,故本文在第六节专门讨论了调查实验法相比于其他研究方法的局限。

四、调查实验法的案例分析
在这一节中,我们通过实际分析一个案例来具体介绍调查实验法的操作方法和步骤。此项研究考察了家庭和人口研究领域的一个重要话题:制度环 境(即家庭政策)如何影响年轻人的结婚意愿 (参见 Gong & Wang, 2021)。数据来自2008—2009 年日本婚姻与生育调查。
(一)方法的选择:为什么要做调查实验?
尽管社会学家常常将制度环境作为解释变量(Kalev et al., 2006),但是使用调查法或实验法考察制度环境的影响面临着几大问题。就调查法而言,研究者可以使用观测性数据考察在家庭政策实施之后人们结婚意愿的变化。然而,因为制度环境在短时间内不易变化,且其变化与社会文化观念有内生性的联系,所以如何准确测量制度环境的变迁,并通过反事实框架来识别制度环境的因果效应,一直是困扰社会学家的难题(Li & Wang, 2022)。就田野实验而言,研究者可以在一个组织内部随机推行家庭政策(Kelly et al., 2014),然后观测实验组和控制组在结婚意愿和行为上的区别。然而,此种田野实验使得同一公司的部分员工获得特别优待,在实施过程中面临着伦理和组织内部政治的难题。就算实验得以在一个或几个组织内小范围展开,也因为同样的伦理和成本问题而难以在国家层面随机实施,所以研究者很难保证组织层面的结论在社会层面具有普适性(Pedulla & Thébaud, 2015)。此外,组织内田野实验难以避免控制组的员工因为得知公司针对同事的实验干预而改变自己的行为和态度,如觉得自己不受公司重视而产生消极情绪。也就是说,田野实验往往难以避免干预溢出效应对因果推断的影响(Gerber & Green, 2012)。综上所述,运用调查实验法,随机对代表性受访者披露不同类型的制度安排信息,我们可以探究实验组和控制组之间结婚意愿的系统性差异以及背后的因果机制。同时,将调查实验和互联网平台相结合可以让我们在短时间内获得巨大样本,从而考察因果关系的异质性。所以,调查实验法不仅成为研究制度环境和结婚意愿之间因果关系的有效手段,也可以为大型社会政策的制定提供先导研究和有效性评估。
(二)研究设计
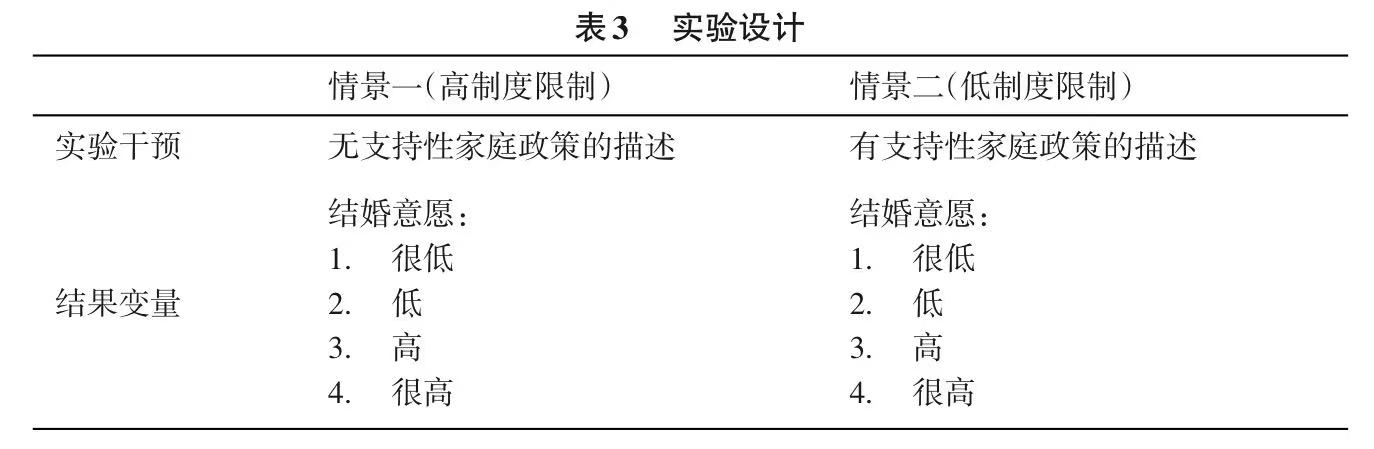
研究根据加里·贝克尔(Gary Becker)的婚姻理论,假设婚姻市场中的制度限制(即缺乏高程度的支持性家庭政策)是造成年轻人结婚成本高和结婚意愿低的重要原因(Becker, 1991)。因此,更具支持性的家庭政策(比如配偶收入减税更多,育儿补贴更多,配偶雇佣保险更优惠等)可以降低结婚成本,从而有助于提高年轻人的结婚意愿。然后,研究根据假设确定实验组和对照组,撰写相应的情景描述。在此研究中,我们采用的是单因素实验设计,将制度环境分为高制度限制和低制度限制两种,受访者在随机阅读其中一种描述后,选择其结婚意愿(见表3)。在高制度限制组中,研究未描述支持性的家庭政策,只给出了关于日本婚姻现状的背景说明。在低制度限制组中,研究不仅给出了背景说明,还描述了支持性的家庭政策。值得强调的是,这两组不同的问卷在其他方面的表述都是相同的,有效地控制了实验干预以外因素的影响,即高制度限制组和低制度限制组仅在家庭政策的描述方面不同。如果两组表述有其他方面的不同,就违反了实验设计其他条件不变(ceteris paribus)的原则。
除了实验问题以外,研究还在问卷中加入了其他人口和经济社会变量,比如性别、受教育程度、收入等(Xie & Dong, 2021),以用来进行亚组异质性分析。接下来,我们将研究总体定义为20~40 岁的未婚且无子女的男女,由调查公司MacroMill来收集全国样本。MaroMill通过一系列征募方法(比如广告推送、邮件、网络公关)创建了日本最大的网络受访者数据库,并在数据库中进行随机抽样。为了保证样本的代表性,MaroMill根据日本人口普查在年龄、性别、地域和受教育程度方面对样本进行加权。研究通过对比加权样本和人口普查,发现关键变量的分布在两组数据中保持一致,进一步证实了样本的代表性。
(三)数据的收集与处理
研究通过随机抽样来发放网络问卷,并运用电脑产生随机数的方式,向受访者展示其中一个版本。最终调查的完成率为 79% ,样本数为 6544。由于研究对最终样本进行了加权,所以无应答人群并不会影响研究的代表性。与其他实验法一样,调查实验的核心是分组的随机化(Shadish et al., 2001),所以研究在数据收集完成后,对不同分组间与研究问题相关的社会人口学变量做了平衡性检验(balance check),发现实验干预与否和社会人口变量没有显著关系,从而保证这一内部效度前提的成立。另外,调查实验法尤其重视实验现实主义(experimental realism),即实验干预对因变量发生了有效作用,而非其他黑箱影响或误解等外部因素所致,从而排除替代性解释(alternative theories)(Stinchcombe, 1987)。所以,研究还可以设置操控检查(manipulation check),比如使用一个关于实验干预的多项选择题来检验受访者是否充分记得和理解了情景描述的内容(比如家庭政策的信息)。
(四)数据分析与结果讨论
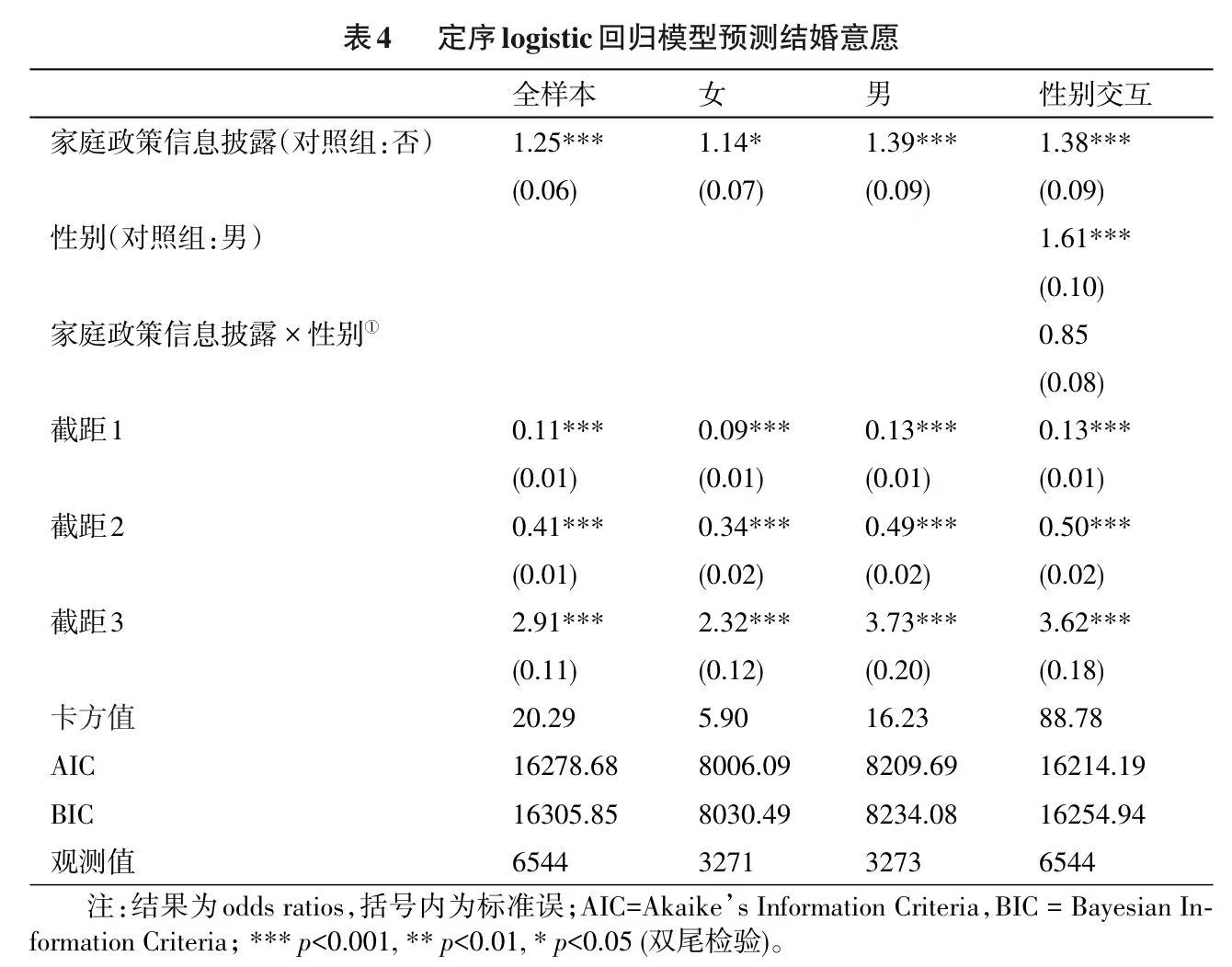
由于研究的因变量是定序变量并通过了平行性假设,所以使用定序logistic 回归来分析家庭政策信息披露对于年轻人结婚意愿的影响(见表4)。研究发现,在全样本中实验组(接受了政策信息披露)结婚意愿的OR 值是对照组(没有接受政策信息披露)的1.25 倍,并且在0.001 水平上显著。这意味着接受家庭政策信息披露可以显著提升年轻人的结婚意愿。接下来,我们进行了异质性分析,发现处理效应在男女样本中分别显著。为了检验性别差别,我们纳入了性别的交互项,然后预测并比较了边际效应,从而发现交互项是不显著的。除了性别以外,研究还可以考察处理效应在不同受教育程度、收入等多个社会经济特征中的异质性。研究最后进行了一系列稳健性检验,比如把因变量合并成二分变量进行logistic 回归,发现结果保持一致。总体来说,研究的结论说明了日本年轻人的低结婚意愿是缺乏支持性家庭政策的制度限制造成的。这一结果对于提升结婚意愿和促进生育率有着重要意义。
(五)注意事项
关于研究设计有几个值得注意的地方。第一,研究的总样本量为6544。尽管样本量的确定要基于功效分析(power analysis),在第一类错误和第二类错误的权衡间做出合理的选择,最近的一些调查实验的样本量大于这个数量(Auspurg et al., 2017),更大的样本量为异质性分析创造了条件。第二,在设计问卷时,研究者可以使用在调查中常用的认知问讯(cognitive inter⁃ viewing)等验证问卷效度的方法,在大规模发放问卷前,确保受访者准确地理解了问题的含义和答题的指示(Schaeffer & Presser, 2003)。在设计实验时,可以使用在实验中常用的实验试测(pretest)等方法,确保实验干预是有效且不易产生歧义的。第三,由于此研究只作为案例展示,所以实验假设和设计没有在第三方平台预注册(pre-registration)。近年来,随着对社会科学再现危机的讨论不断增加,预注册已经在临床医学、社会心理学等领域成为标准操作,甚至成为在一些学术期刊上发表实验研究的必要条件(Munafò et al., 2017)。由于实验法可以在一定程度上避免 p 值操纵等问题,提高研究的信度,在开展实验前,详细登记调查实验的研究假设、设计和步骤,是值得大力提倡的。第四,研究者可以在研究设计中纳入变量来测量家庭政策影响的机制,并使用中介分析来探究不同机制的中介效应(Gerber & Green, 2012)。比如,在此研究中家庭政策可能通过降低结婚的物质成本,有助于人们平衡工作和家庭,或提升人们对国家经济发展的信心等不同渠道提高年轻人结婚意愿。
表5 描述了一个较为完整的调查实验的流程,可以为未来的调查实验研究提供参考。

五、调查实验法在社会学中的应用场景及价值
调查实验法还可以应用在其他一系列场景来对人们的态度、情绪、价值观以及决策进行研究。总体来说,调查实验法在丰富社会学研究话题方面有两大贡献。第一,在决策和态度研究中,析因调查实验可以研究人们在决策过程中对不同方面的权衡取舍以及背后机制。第二,调查实验可以通过创建虚拟情境来研究现实中很少发生或者未来将要发生的事件。接下来,我们将对调查实验法在社会学三大核心领域的应用进行系统回顾,并通过实例详细阐述其价值。
(一)社会分层和不平等
社会学家常常关注性别、种族、教育、移民状态等特征对个人发展机会的影响,并且认为它们是造成社会分层和不平等的重要原因。调查实验法为社会分层和不平等的研究提供了新的理论视角。比如在劳工市场领域,传统调查研究主要关注劳动者的特征如何影响他们的收入(即劳动供给方),而调查实验通过向雇主随机发放带有不同特征的简历问卷,研究雇主的决策如何影响劳动者的就业和升迁机会(即劳动需求方),为劳工市场不平等和社会分层研究提供了全新的视角。迪斯塔西奥和范德伍尔夫赫斯特利用调查实验法比较了荷兰和英国信息技术领域的雇主,发现荷兰雇主对简历中专业匹配程度的关注度大于成绩,而英国雇主对在校成绩的关注度大于专业,反映了社会环境对招聘决策的影响(Di Stasio & van de Werf horst,2016)。佩杜拉的调查实验研究发现在美国有过非正式工作经历的应聘者会得到雇主较低的评分,这主要是因为雇主认为这些应聘者缺乏竞争力和良好的工作态度,进而揭示了雇主决策过程中的重要机制(Pedulla, 2016)。在这些案例中,研究者利用调查实验法的优势,探索各种因素对结果变量的交互影响和内在机制,为社会学家拓展多因一果和复杂因果的社会学理论提供了有力的工具(彭玉生, 2011)。
另外,调查实验法在种族、移民歧视和不平等的领域也有广泛运用。保罗·施耐德曼(Paul Sniderman)是调查实验法的奠基人之一,他利用这个方法在种族歧视领域做了很多工作。比如,他在代表作《种族的伤疤》(The Scar of Race)中将受访者随机分组,然后询问政府是否应该帮助失业的美国
白人或黑人,实验结果揭示了美国存在严重的种族歧视(Sniderman & Piazza, 1993)。还有一项研究利用调查实验法让受访者评估拥有不同特征的移民,并考察受访者多大程度上会因为经济上的考虑反对国外移民,如担心增加本国财政负担和减少本国人就业机会。结果发现经济原因不能完全解释受访者反对移民的态度,揭示了非经济因素如民族优越感的重要影响(Hainmueller & Hiscox,2010)。另一项在中国开展的调查实验发现,对于从农村到城市的移民来说,是否拥有户口和住房对他们的城市认同感有着重要影响(Chen et al.,2020)。
值得指出的是,社会分层的指标在不同国家和时代背景下是不同的(Liebe et al., 2020)。比如,在研究户口、体制身份等在中国非常重要的社会特征的因果效应时,调查实验法尚未广泛运用,这就为我国社会学家使用调查实验法,基于中国的社会情境,对社会学理论做出贡献提供了机遇(Chen et al., 2020)。
(二)社会规范
社会规范是社会学的核心议题,是构成一个社会法律、道德和社会治理的基础。同时,对社会规范的理解在不同人群、不同文化和不同情景下也有着很大区别。所以,调查实验通过创建带有不同特征的虚拟情景可以深入考察人们对社会规范的理解和定义。比如,人们对分配正义(distributive justice)的理解是社会政策和立法的重要基础。罗顿和桑乔姆利用调查实验法研究了不同群体对于不同分配政策的公平感知。结果发现,所有人都认为鼓励社会流动和帮助穷人的政策是公平的,但是对于减少富人财富的政策,低收入者认为是公平的,而高收入者则相反(Rodon & Sanjaume,2020)。在政府廉政建设方面,调查实验法可以用来研究民众对处罚腐败官员的态度,即他们在何种情况下应该受到多大程度的惩罚。温特斯和维茨·夏皮尔的研究通过创建虚拟情景发现,在巴西只要市长涉及腐败,民众都认为他应该受到惩罚。但是当市长没有直接参与腐败,而只是和市长相关的行政人员参与腐败,民众要求对市长的惩罚力度会减轻(Winters & Weitz-Shapiro, 2016)。总体来说,这些案例说明了调查实验法对于研究社会规范、道德和制度的形成和变迁有着重要意义,同时对于法律社会学和越轨社会学的经验研究有着重要启示。
(三)社会政策
此外,调查实验法的一个优势是可以通过创建虚拟场景让受访者评价现实中很少或尚未发生的政策事件,而在调查等回溯性的研究中,这些很少或尚未发生的政策或事件是很难被考察的。比如,有研究利用调查实验法考察人们对于中国政府吸引海外人才政策的支持度,研究随机展示了针对不同海外人才,比如学生、教授、企业家等的政策,发现针对教授和企业家的政策获得了更多的支持(Tai & Truex,2015)。孟天广等(2015)考察了上级政府和本地公民意见对于地方财政决策的影响,发现上级政府和本地公民意见可以影响经济发展领域而非民生领域的财政支出。贝尔诺等利用情景调查实验法研究人们对于环保政策的态度,发现当公民社会组织参与到环保政策的制定中,人们对于环保政策会有更高的支持度(Bernauer et al., 2016)。除此之外,调查实验设计还适用于婚姻家庭政策、移民政策和其他社会福利政策的研究,以考察民众对尚未公布实施的社会政策的反应。随着社会科学从解释向预测发展(陈云松等, 2020),部分学者提出了以实际问题和解决方案为导向的社会科学范式(Watts, 2017)。尽管使用情景描述受访者对政策的主观反应有一定的局限,但这类前瞻性的研究可以为政府科学决策提供依据。
(四)社会调查方法论
除了以上的应用之外,调查实验还可以运用于改进调查和测量方法。在一篇论文中,舒曼和普莱斯比较了封闭式和开放式提问对受访者回答的影响,发现不同提问方式会导致显著不同的答案,这种差异对于低教育群体尤其明显(Schuman & Presser,1979)。近年来,克罗斯尼克也使用调查实验方法对问卷设计进行了广泛的研究。比如,在一项研究中,章等运用调查实验法发现,通过网络收集的数据相比于通过电话访谈收集的数据有着更高的效度并且有着更低的测量误差(Chang & Krosnick,2010)。综上所述,调查实验法不仅加深了我们对调查研究方法论的认识,也为调查设计的改进和创新提供了一个有力的工具。
我们发现,之前所有使用调查实验法的研究都发表在英文期刊或少量中文非社会学期刊上,所以我们期待该方法未来被更多的中国社会学研究者使用。同时,我们也建议国内现有的全国代表性社会调查,比如中国综合社会调查、中国家庭追踪调查等,有选择地纳入一些经典的实验设计,从而为调查实验的应用开辟更多途径。
六、结 论
(一)调查实验法的局限
尽管使用调查实验法可以获得内部效度和外部效度都较高的结论,但这种方法仍然具有一定的局限性。这一节将简述这些局限和常见的应对策略。
第一,类似于调查法,调查实验法虽然可以通过概率抽样实现较高的外部效度,但其外部效度仍受到抽样框选择、问卷回收率、有效回答率等方面的制约(风笑天, 1994)。目前,世界上主要的有国别代表性的社会调查回收率多为 60%~70%(参见中国社会综合调查、General Social Survey、European Social Survey),虽然我国的一些社会调查有效回答率较高,但无应答误差
(non-response error)依然是调查实验研究者需注意的问题(梁玉成, 2011)。比如,相比于一般社会调查,调查实验法需要受访者投入更多时间和注意力来阅读实验情景描述,这就对受访者提出了更高的要求,可能会降低有效回答率和外部效度(Schaeffer & Presser, 2003)。对此,研究者在分析数据的时候,可以采用统计方法来检验应答者和无应答者在社会人口学变量上的差异(任莉颖等, 2014)。此外,只要在有效样本中随机化是有效的,无应答误差对结论内部效度的影响就较小(Shadish et al., 2001)。但是,如果某个情景描述由于社会期许偏差等原因,使具有某一与研究问题相关特点的受访人群系统性地拒绝回答,就会影响到随机化这一因果推断的基本假设的成立(Gaines et al., 2007)。这一问题因为“心理二重区域”的存在,在我国问卷调查中尤为普遍(李强,2000)。因此,在进行稳健性分析时,研究者应进行平衡性检验,即检验有效样本中各个随机分组之间在与研究问题相关的社会人口学变量上是否有系统性差异。
第二,实验法在实现内部效度上有独特的优势,且调查实验法在各种实验方法中外部效度较高,但这种方法仍然有实验法普遍存在的几个局限。首先,外部效度在实验中有两种不同的定义:既可以指样本在总体中的代表性,又可以指实验干预与实验被试(即问卷受访者)日常生活经历的相似性,即生活现实性(mundane realism)(Berkowitz & Donnerstein, 1982)。尽管大多数调查实验使用概率抽样和大样本,对总体的代表性在各种实验方法中是具有创新性的,但由于阅读情景描述、回答多项选择题等研究形式的限制,调查实验的生活现实性低于田野实验等方法。特别是当析因调查实验有多个维度时,排列组合有可能会出现不现实的情况,需要研究者仔细检查并排除。在政策效应评估中,调查实验主要研究的是受访者对政策信息的主观反应,要准确估计政策效应,尤其是政策措施在具体社会情境下与其他制度、文化因素相互作用后总的效应,还需要依靠田野实验和其他收集实地数据的研究方法(Gerber & Green, 2012)。因此,研究者需要清晰地定义实验干预的内涵,避免过度地拓展实验结论的应用范围(Liebe et al., 2020)。其次,和其他实验方法一样,调查实验法对概念效度的要求较高(方文, 1995)。比如,受访者可能因为倦怠忽略了情景描述中的随机干预信息,进而产生统计推断中的第一类错误。对此,实验者需要在生活现实性允许的范围内,尽可能凸显实验干预与对照组的区别,必要时配合图片、音频等更加直观的展示方式,但同时也要避免有经验的受访者猜测到实验干预,产生顺从偏差(compliance bias)。再比如,对灵活用工安排的情景描述,可能引发受访者对雇主营利能力正面或负面的联想。尽管在这种情况下,实验干预依然具有内部效度,但研究者需要进一步确认操作化的实验干预准确代表了自变量的理论概念。因此,调查实验法尤其注重排除替代性解释,开展基线调查(baseline survey)和实验后的机制调查(mechanism survey),并进行中介效应分析和亚组之间的异质性分析,以排除其他可能的解释。需要注意的是,调查实验法对机制的分析得出的并不是因果关系,除非研究者在进一步的研究中对中介变量本身做了随机化干预(Shadish, et al., 2001)。
第三,正因为调查实验法结合了调查法和实验法的优点,其适用范围也兼有两种方法的局限性。首先,因为调查实验法具有瞬时性,这种方法难以直接干预在较长时间内形成的社会结构,比如社会的文化观念、个体的社会网络等。尽管部分研究让受访者想象一种新的制度环境,但如前所述,这种方法有生活现实性的局限。但正因为调查实验法不需要实际改变社会结构,因此它赋予了研究者充分的想象力,使研究者可根据社会日新月异的变化,利用针对特定群体的概率抽样和因果推断方法,以较小的成本为政府决策提供扎实的证据(Watts, 2017)。其次,因为问卷形式的限制,调查实验法的因变量多为受访者的主观态度,如结婚和生育意愿、对雇主的满意度、对政府的支持率等。研究者需要依据理论和前期研究,讨论主观态度与客观行为的相关性,及其在理论和实践中的具体含义(龚为纲、朱萌,2018;刘保中等,2014)。最近,一些研究者尝试在调查实验中直接测量受访者的行为,比如在随机展示一段广告后,为受访者提供额外的奖金并询问受访者是否愿意将全部或部分奖金向第三方捐赠,以测量受访者对组织的实际支持情况(Li & Soule, 2021)。使用这类行为变量,可以减少调查法中常见的社会期许偏差等测量误差,有效地弥补态度型因变量的不足。
(二)调查实验法的价值与前景总结
调查实验法同时具有较高的内部效度和外部效度。首先,实验方法被视为因果推断的“黄金标准”,位于科学证据金字塔的顶端(Jackson & Cox, 2013),相比于基于观测性数据的调查统计方法,调查实验法有助于解决困扰社会学家已久的因果推断的“根本问题”。此外,开展进行了预注册的实验,可以验证现有的观测性研究,帮助化解社会科学的再现性危机(陈云松、吴晓刚, 2012)。其次,调查实验法以其针对特定人群进行概率抽样的优势,可以为构建基于中国社会且具有普适性的社会学理论提供经验证据。调查实验法一定程度上克服了实验室实验小样本、任意抽样和田野实验操作难度大、成本高的局限,便于实验方法在社会分层与不平等、社会和人口政策等研究领域的推广。近年来,我国社会学家开展了一系列具有全国代表性的社会调查,为调查实验法的运用提供了土壤。此外,随着互联网的普及和电脑辅助调查技术的发展,网络调查实验可以和大数据、机器学习等新兴的定量研究方法相结合。最后,前瞻性的调查实验法可以探索公众对尚未实施的社会政策的主观反应,为社会治理和经济建设提供科学决策的依据。尽管和任何研究方法一样,调查实验法的适用范围具有一定的局限性,但它作为一种新的因果推断方法,在中国社会学研究中会有广泛应用和重要价值。
(注释与参考文献从略,全文详见《社会学评论》2022年第6期)