社会学方法
社会学量化研究控制变量方法的反思与超越
内容提要:受制于可操作性、研究伦理等问题,社会科学量化研究者一般借助统计隔离方法来应对内生性问题,其中,控制变量是最常见的方法。以社会学量化研究为例,对近十年发表于《社会学研究》上的149篇定量文献的分析发现:控制变量是社会学量化研究使用率最高的统计隔离方法,使用率为88.59%。但在使用中普遍存在变量纳入的滥用化、变量选择的趋同化和变量分析的浅薄化等失范问题,这是社会学定量研究泛化、能力弱的根本原因。根据第三方变量的作用形式可以总结出三种基本类型:形式为X→Z1→Y的中介因子、形式为X←Z2→Y混沌因子和形式为X→Z3←Y对撞因子。其中,混沌因子需要控制,借以实现研究者准确评估核心变量之间真实因果关系的目的;对撞因子则不适合,予以强行控制的结果是造成虚假因果;而对中介因子的控制是否合适需要视具体情况而定,假如是完全中介,控制中介因子的后果是完全阻断X到Y的信息传递路径,导致两者不相关,而如果是部分中介,则可以通过控制中介因子评估X与Y的直接因果效应。对第三方变量作用形式的判定是规范控制变量方法使用的首要步骤,不能仅仅因为某个变量同时与核心变量X和Y都有关联就认为它是混沌因子而加以控制,否则可能不仅没有降低反而增加模型的混沌效应。新出现的机器学习建模方法可以帮助研究有效识别变量类型,推动控制变量方法使用的规范化。
关键词:控制变量/社会学量化研究/规范化/Z变量类别
作者简介:冯帅帅,武汉大学社会学院博士研究生,主要从事大数据与计算社会科学研究;罗教讲,武汉大学社会学院教授,主要从事大数据与计算社会科学研究
一、问题的提出
无论是自然科学还是社会科学,只要冠之以科学之名,大都以探究变量关系、揭示现象或事物背后的因果机制,总结自然和社会的因果规律作为自身的核心任务。从方法角度出发,追求这一目标的关键在于能够识别、隔离和控制那些干扰因素,即可能同时对解释变量和目标变量产生作用的其他相关变量,学术界将这种现象称作“内生性问题”(endogeneit),将这种变量叫作“混沌因子”(confounding variable)。只有在有效控制这些混沌因子的基础上,研究者才可能做到净化变量关系中的混沌/内生效应,更准确地评估解释变量与目标变量之间的因果关系,排除分析结果的替代性解释,最终得出科学和有价值的研究结论。到目前为止,研究者用以应对“混沌因子”或“内生性问题”的方式主要有两种:实验或准实验法(experimental or quasi-experimental)和统计隔离法(statistical mechanisms)。在化学、生物等自然科学以及心理科学研究中,实验法或准实验法的应用非常广泛。美国心理学家费斯汀格和卡尔史密斯的认知失调实验是典型案例之一,他们在实验设计中故意向被试者隐瞒真实的实验目的,采用排除法(elimination method)隔离被试者的主观预期对实验结果的影响。遗憾的是,受制于可操作性、变量关系复杂、研究伦理等诸多因素,社会学、政治学和管理学等社会科学领域学者无法或很难借助实验方法开展研究,使用统计隔离的方法在实践上更为可行。借助统计隔离法可以在数学上有效消除与非核心变量相关的方差,帮助研究者接近更加真实的因果关系。统计隔离的具体方法有很多,被广为使用的方法包括工具变量(instrumental variable)、双重差分方法(difference-indifferences method)、倾向值匹配(propensity score matching)、固定效应模型(fixed effects model)、同胞效应(sibling effects),以及在很多社会学量化研究者看起来最为初级,但使用率却是最高的控制变量法(control variable)。
控制变量法是指研究者基于常识经验、理论设想和文献分析等基础上,对影响核心变量(解释变量和目标变量)的其它因素或条件加以控制,使其按照特定要求发生变化或者保持恒定,以帮助研究者探寻核心变量真实因果关系的一种方法。在具体方法使用中,研究者不是通过实验或准实验设计使相关因素在样本或环境中保持恒定,而是测量可能与核心变量有关系的变量或标准,并将其包含在后续分析中。研究者一般会在量化研究中设置多个模型,并将他们所选择的控制变量置入模型Ⅰ中,然后采用逐步纳入的方法将核心解释变量逐步置入余下模型(模型Ⅱ、模型Ⅲ等),通过Δ 评估混沌因子的效应,基于此分析在混沌因子控制下解释变量与目标变量之间的关系,这已经成为一种标准化操作模式。
近年来,控制变量使用规范问题得到西方研究者的重点关注,如Becker通过分析2000-2002年三年发表在管理学院学报(AMJ)、《行政科学季刊》(ASQ)、《应用心理学期刊》(JAP)和《人员心理学》(PPsych)四大期刊中的60篇文献样本发现,大约63%使用控制变量法的研究没有为控制变量提供明确的理由;在Becker研究的基础上,Atinc等人分析了四大期刊更长时间内、更多文献样本的控制变量使用情况;Bernerth和Aquinis回顾了2003年至2012年发表在顶级管理学期刊上的580篇实证研究,发现2003年只有5%的研究为控制变量提供了充分的理论基础,2012年这一数据下降为3%。相关建议也已经加入Academy of Management Journal(AMJ)和Journal of Organizational Behavior(JOB)的审稿标准中。
相较而言,国内学者对控制变量用法的理论和经验讨论明显不足,仅曹江雨等人[16]的《组织管理研究中的控制变量使用:问题与策略》一文对组织研究中的控制变量使用规范问题展开讨论。他们通过对2016-2018年刊登在四本管理学和心理学权威中文期刊(《管理世界》《南开管理评论》《心理学报》《心理科学》)上的113篇组织行为学文献分析发现,虽然有69%的研究者为至少一个控制变量的使用提供了一定依据,但是其中只有3篇研究是基于明确的理论依据来选择控制变量的,且在2018年发表的研究中该数值为0。目前尚未发现社会学领域有学者展开相关研究。基于此,本研究在分析2010-2019年发表在《社会学研究》杂志上的149篇定量文献的基础上,总结社会学量化研究中的控制变量使用情况和其存在的问题,并借助因果图示和案例分析的方式讨论社会学量化研究控制变量使用规范的重要意义。上述内容将主要围绕以下几个问题展开:第一,控制变量法要解决什么问题?如何实现?第二,控制变量是否越多越好?第三,如何规范控制变量方法的使用?
二、控制变量的内在机制与先在假设
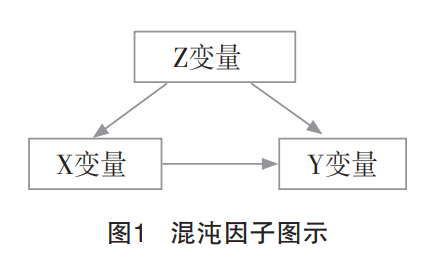
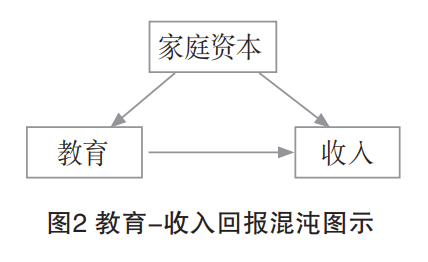
当一个变量同时影响到选择处理的对象(自变量X)和目标对象(因变量Y),偏误就产生了。对社会学研究而言,困难之处在于这类混沌因子有些是已知的(通过常识或者相关文献研究),但更多是未知或者是疑似的。以因果图示的方式可以清晰地向我们展示混沌因子的作用形式。在图1中,变量Z即自变量X和因变量Y的混沌因子。从该因果图可知,真正的因果效应X→Y与由X←Z→Y诱导的伪相关混合在一起,这造成的后果有两种:其一,X与Y确实存在真正的因果关系,但该因果关系受到外生变量Z的部分影响;其二,X与Y之间没有因果关联,统计模型呈现的显著性相关是因Z变量导致的伪相关。比如研究教育与收入的关系,假如我们收集了北京大学1000名毕业生的教育—收入数据,分析发现,教育与收入存在显著的正向关系。但是我们忽略了一个重要变量——家庭资本。相较而言,与农村家庭学生相比,城市家庭学生的家庭资本更丰富,具体体现在知识面、社会关系网、技能掌握、经济支撑等方面,而这些因素实际上对学生教育机会获得和收入状况同时起到一定作用,也即我们提到的Z变量,因果图示如图2所示。那么教育与收入之间的相关关系究竟是真实因果还是Z变量(家庭资本)下的虚假因果呢?如果缺失关于家庭资本的数据,显然我们将无法从教育的效果中区分和“提纯”真实因果。反之,如我们掌握了Z变量(家庭资本)的数据并将其控制住,那我们就可以很轻易地识别教育与收入之间的真实因果,并计算出相应的影响系数。
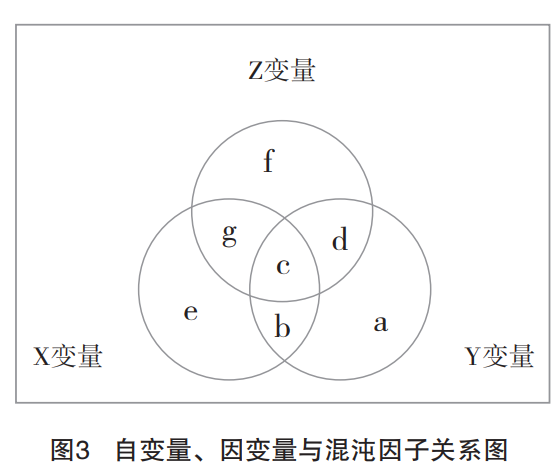
理解控制变量的作用机理需要掌握统计学的两个基本概念:偏相关(partial correlation)和半偏相关(semi-partial correlation)。如图3所示,偏相关是指同时从X和Y中移除Z与X、Y的共同变异(c+d+g)后,剩余X(b+e)能够解释的剩余Y(a+b)中的变异,偏相关系数的平方(即决定系数 )为b/(a+b)。半偏相关是指单独移除Z与X的共同变异(c+g)或单独移除Z与Y的共同变异(c+d)后X与Y的相关。研究者在分步回归分析中实际讨论的,是移除了Z与X的共同变异(c+g)后,剩余X(b+e)能够解释的Y(a+b+c+d)中的变异。移除了Z对X的影响后的半偏相关系数的平方为b/(a+b+c+d),与研究者经常使用的![]() 等价。使用统计方法对额外变量的影响进行控制后,研究者在假设检验中实际使用的前因变量X已经不再是原始的X(b+c+e+g),而是移除了前因变量X和额外变量Z的共同变异(c+g)后的剩余前因变量X(b+e)。这一对概念对于理解控制变量使用相关问题非常重要。
等价。使用统计方法对额外变量的影响进行控制后,研究者在假设检验中实际使用的前因变量X已经不再是原始的X(b+c+e+g),而是移除了前因变量X和额外变量Z的共同变异(c+g)后的剩余前因变量X(b+e)。这一对概念对于理解控制变量使用相关问题非常重要。
偏相关系数和半偏相关系数的计算公式如下:
公式1(偏相关系数):
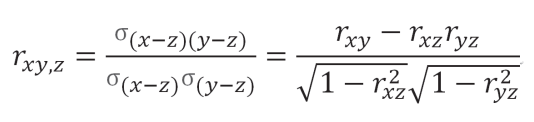
公式2(半偏相关系数):
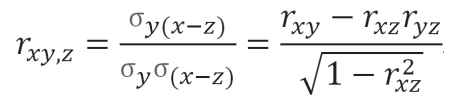
控制变量用法背后有三个条件假设:其一,混沌因子会污染核心变量之间的真实性关系,如果事先未对混沌因子施加干预或控制,那么分析得出的解释变量与目标变量之间的关系就是虚假或夸大的,结果是,尽管常常缺乏事实依据,但普遍认为控制变量的加入会净化结果并揭示“真实”的关系;其二,与不包括控制变量相比,那些包括控制变量(尤其是多个控制变量)的分析模型是一种更安全、统计上更为可靠的方法,研究者可以通过在分析中控制混杂变量来消除预测标准污染;第三条隐藏的假设是,控制变量的测量通常是可靠的。相较于核心变量的操作化测量,研究者很少关注控制变量测量的信度和效度问题。重要的是,当事实情况违反这一假定时——即控制变量测量存在偏误,模型所解析出的方差可能表示控制变量和核心变量之间的共享方差(共享方差=真实方差+误差方差),如果此类情况发生,那么就算控制住了混沌因子,也无法完全净化混沌因子所带来的混杂效应。实际上,上述三条假设中的每一条都依赖于相当大的推论性飞跃,况且即使在三个假设统统满足的情况下也会存在许多潜在问题。一方面,包含控制变量的模型不仅会降低可用的自由度和统计能力,而且有可能减少有价值结果中可解释的方差量。也就是说,当控制变量与预测变量相关时,结果可能看起来像预测变量与目标变量不相关或意外方向的相关,而实际上对零阶相关性的分析——不纳入控制变量情况下——可能出现完全相反的结果;另一方面,过多强调和排除控制变量模型的可解释方差量也可能导致错误的结论,即预测变量与结果变量的相关性实际上不存在。因此,控制变量的纳入或筛选对理论和实践都具有重要意义,因为这样的决定会对研究结果造成实质性的改变,并限制了复制、概括和延展研究结果的能力。
三、越多越好?控制变量的失范表现
控制变量方法以成本低廉、操作方便等优势而深得研究者青睐,被学者广泛应用于各类量化研究中。但奇怪的是,在社会学定量研究中,研究者对控制变量方法是既重视又轻视的,重视体现在,使用控制变量方法来解决内生问题几乎成为不会被质疑且使用比例最为广泛的统计隔离方法;而轻视体现在,较少有研究者关注和讨论控制变量的合法性问题,关于控制变量的选择、控制变量的数量、控制变量与核心变量的复杂关系等问题往往被研究者一笔带过,或者避而不谈。控制变量就像一个任人打扮的小姑娘,放什么、放哪里、什么时候放,全凭研究者喜好。出现这种现象的可能原因是研究者把控制变量仅仅当作研究设计和数据分析中的次要部分,并且控制变量对研究结果的影响不容易被发现。但是,选择不恰当的控制变量不仅会影响不同数据分析结果的比较,还会降低研究结果的信度与效度。
我们仍以上文提及的“教育—收入”研究为案例,假如只有大学教育与收入两个变量,我们完全可以基于两组数据的收集,借助回归模型拟合出一条回归直线,典型的线性回归公式可表达为:但事实却没有这么简单,已有研究发现,性别、年龄、政治身份、家庭资本(包括经济资本、文化资本、政治资本、社会资本)、户口等多个因素同时与收入和大学教育存在某种变量关系,同样可以用数学公式表达:我们当然可以将上述所有混沌因子给“控制”起来,但这种做法存在一定的风险。诚如国内学者胡安宁所做的总结:
首先,如果将这些混沌因子作为自变量放进回归模型,我们就潜在假定了这些混沌因子对收入的效果与大学教育对收入的效果之间存在一种线性关系,然而这种线性假定缺乏理论和实践依据。也就是说,我们不能简单认为性别对收入的影响与大学教育对收入的影响是累加的。其次,大学教育的回归系数代表的是一种“平均”效果。这个系数所回答的问题是:在人口中任意选取一个人,如果他接受的是大学教育,他的收入会是什么水平。然而,在探索因果关系时我们所关心的问题则是:1)一个任意选取的大学生如果一开始没上大学的话会是什么收入水平;2)一个任意选取的非大学生如果上大学的话会是什么收入水平。这是两个不同的问题,而回归模型则没有区分它们,只是取了它们的平均水平,这样做无疑会带来误差。最后,由于混沌因子与我们关心的自变量之间存在相关性,简单地将混沌因子纳入多元回归模型有可能产生共线性问题。
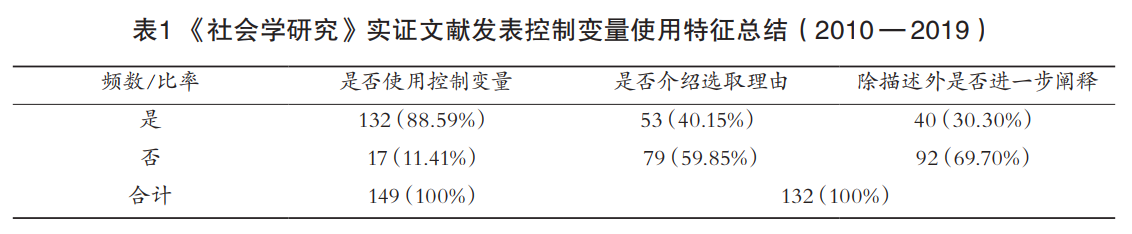
这就意味着控制变量法并非我们所设想的那么可靠,在控制变量法广泛使用的今天,我们需要予以重新认识和反思。《社会学研究》杂志是社会学领域的权威期刊,在该期刊发表的论文在一定程度上被视为评判社会学学者专业素养的标准之一。就投稿角度而言,《社会学研究》杂志对稿件的方法使用没有明确限制,所刊论文包括理论研究、定性研究、定量研究、新兴的计算社会科学研究等多个类别。借助中国知网平台,笔者对《社会学研究》2010-2019年10年间刊发的149篇量化研究论文进行了量化分析。研究发现,其一,在全部的149篇定量文献中,有132篇文献控制了至少一个变量,控制变量方法使用率为88.59%;其二,社会学定量研究在控制变量的使用中存在失范问题,包括变量纳入的滥用化、变量选择的趋同化和变量分析的浅薄化。具体分析内容如表1和图4~6所示。
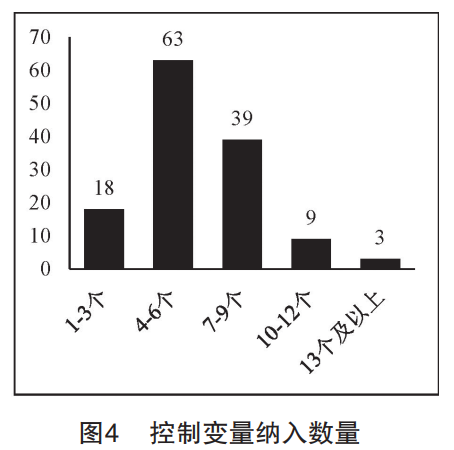

第一,变量纳入的滥用化(越来越多)。如图4所示,在132篇使用控制变量法的定量文献中,控制变量数量在1~3个的频次为18,占比13.64%;控制变量数量在4~6个的频次最高,为63,占比47.73%;控制变量数量在7~9个的频次为39,占比29.55%;10~12个的频次为9,占比6.82%;13个及以上的频次为3,占比2.27%。并且,其中一篇研究文献的控制变量竟高达21个。越来越多的量化研究者无时无刻都处于精神紧张状态,总是担心自己的研究因无法穷尽所有混沌因子而得到错误的模型和结论,于是陷入一种“过度控制”(over-control)的失范路径中。美国政治媒体人埃兹拉·克莱因曾公开指出社会科学量化研究的这种“过度控制”问题,指责他们经常对过多的变量进行控制,甚至控制了不该控制的变量,“你在各种研究中都能看到它。‘我们控制了……’然后一张关于被控制的变量的列表就开始了,而且这个列表往往被认为越长越好:收入、年龄、种族、宗教、身高、头发颜色、性取向、健身频率、父母的爱、偏好可口可乐还是百事可乐……就好像你能控制的东西越多,你的研究就越有说服力,或者至少看起来如此。控制可以带来专一性和精确感……但有时,你控制的东西过多了,以至于在某些时候,你最终控制了你真正想要测量的东西”。克莱因提出了一个合理的担忧,研究者对于应该控制和不应该控制哪些变量感到非常困惑,所以默认的做法是控制他们所能测量的一切。目前绝大多数研究都采用这种做法,这的确是一种可轻松遵循的、便捷的、简单的程序,但它既浪费资源又错误百出。
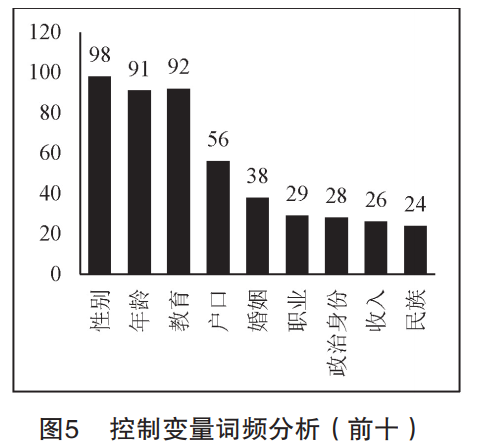
第二,变量选择的趋同化(越来越像)。笔者将132篇使用控制变量方法的定量文献中的控制变量文本摘取出来,合并创建了“控制变量选择文本库”,总字数为3534,并借助Python3.0的文本分析(中文分词、词频统计和文本词云)功能进行了相关分析,结果如图5和图6所示。图5是“控制变量选择文本库”中出现频次排名前十的变量名称,其中,性别、教育和年龄三个变量出现的次数均在90次以上,也就是说,在社会学量化研究中,该三个变量出现在研究者控制变量列表中的频率高达74.24%、69.70%和68.94%,显然是典型的“万金油”式的控制变量。我们不禁要质疑,社会学量化研究的主题那么广泛,内容涵盖社会资本、阶层感知、幸福感、信任、不平等、健康、风险感知等诸多议题,何以性别、教育和年龄有这么大的“能耐”竟得到学者如此钟爱。类似地,美国学者Bernerth和Aguinis收集了2003-2012年发表在AMJ、ASQ、JAP、JOM和PPsych四大人力资源管理和应用心理学领域权威期刊的580篇定量文献,分析发现,在具有明显不同理论基础的研究领域中,绝大多数研究都将一些简单的人口统计学因素,即性别、年龄、任期,作为研究的控制变量,也很少有学者对控制变量与核心变量之间的关系做出明确解释,并且控制变量的做法在过去十年中变化不大。控制变量选择趋同化的原因可能是:其一,凸显研究科学性。变量的内生性问题已然成为量化研究本身的内生性问题,在这种情况下,如果缺失统计控制方法,可能会降低分析结论的科学性。其二,降低研究者负担,当研究者未对混沌因子做深入考察和理论分析时,“随大流”式的控制变量选取就成为部分研究者的合适选择。
第三,变量分析浅薄化(忽略内在关系)。该现象主要体现在控制变量选取和变量解释两个过程中。其一,由表1内容可知,在132篇使用控制变量法的定量文献中,只有四成(40.15%)左右的文献有对控制变量的选择和使用提供一定的理由,理由主要包括文献资源(即通过综述以后文献)、理论假设(借由研究者理论假设推导)、研究惯例(明确提到“根据研究惯例控制XX变量”)和数据驱动(通过一定的统计方法或数据特征进行选择),其中,文献资源(71.7%)和理论假设(33.96%)是控制变量选择理由出现频率最多的类型。其二,只有约三成(30.3%)的研究者在模型结果分析中对控制变量进行了除基本描述外的进一步阐释,包括讨论控制变量对模型效果的影响、控制变量与核心解释变量或目标变量的关系、回应已有文献等。在社会学量化研究中,控制变量通常被视为“从属变量”而受到研究者的轻视,在一篇典型的社会学定量论文中,研究者一般将主要篇幅拿来讨论核心解释变量的选择及其与目标变量的关系,很少或几乎不去关注控制变量。但是模型不会自主筛选哪些是控制变量,哪些是核心解释变量,在统计模型中控制变量的地位与其它解释变量是一致的。研究者轻视控制变量的可能结果就是,控制变量方法不仅没有起到净化和隔离混沌因子对核心变量“污染”的作用,反而会出现模型中控制变量解释的方差超过核心解释变量的情况,使得核心变量的关系更加模糊,令研究者无法准确解释研究结果。
四、反思Z变量:类别与案例
在图1中我们以因果图示的方式展示了混沌因子的作用机制,混沌因子Z是同时指向核心变量X和Y的。正如我们对混沌因子所做的界定那样:当且只有当Z变量同时作用于解释变量X和目标变量Y时,变量Z才可以被称为混沌因子,需要被控制和隔离。那么,是否能够保证我们控制变量列表中的变量全部是混沌因子呢?或者说,是否所有同时与核心变量X和Y具有关联的第三方变量都是混沌因子呢?参考波尔和麦肯齐的贝叶斯网络模型,我们可以尝试对有别于核心变量X和Y的Z变量做一个简要分类,见图7。

根据Z变量的作用机制我们可以总结出第三方Z变量的三种基本类型或形式,分别是中介因子、混沌因子、对撞因子。
(1)中介因子:X→Z1→Y。这种形似“链条”式的变量关系形式在心理学、社会学、管理学和经济学等领域的定量研究中很常见,一般被研究者称为“中介效应模型”(mediation effect model)。在具体研究中,人们通常将Z1视作某种机制或中介物,它将解释变量X的效应传递给目标变量Y。一个简单的例子是:“橘子汁→维生素C→坏血病”。坏血病曾是历史上对人类健康威胁最大的疾病之一,过去几百年间曾在海员、探险家及军队中广为流行,特别是在远航海员中尤为严重,故有“水手的恐惧”和“海上凶神”之称。1753年,苏格兰海军军医詹姆斯·林德偶然发现此病与饮食有关,并经由英格兰探险家詹姆斯·库克进一步引证下,发现饮用橘子汁、柠檬汁后,可有效治疗和预防坏血病。实际上,橘子汁中包含多种成分,而真正对坏血病起作用的是“维生素C”,假如剔除橘子汁中的维生素C成分,那么“喝橘子汁可以治疗与预防坏血病”的结论将无法成立。这个例子引出了中介效应的一个重要概念点:中介因子Z1会“屏蔽”从X到Y的信息。假如我们将中介因子Z1“控制”起来,那么虽然我们成功阻断X通过Z1向Y传递信息的路径,但是也削弱了(若Z1是部分中介)或可能完全隔绝了(若Z1是完全中介)X与Y的因果效应。
(2)混沌因子:X←Z2→Y。混沌因子Z2通常被视作解释变量X和目标变量Y的共同因子(common cause),它既影响X,同时也对Y施加作用。混沌因子的存在可能造成原本没有因果关系的X和Y在统计学上发生关联,也就是我们在上文提到的内生性问题。如前面提到的“教育←家庭资本→收入”案例,毕业生的家庭资本既影响个体的教育习得机会,同时也影响毕业生的工资水平(如通过找关系),统计学上显著的“教育—收入”正向关联可能在事实上并不存在——即伪相关。如果缺失关于家庭资本的数据,显然我们将无法区分和“提纯”真实因果。反之,如我们掌握了Z变量(家庭资本)的数据并将其控制住,那我们就可以很轻易地识别教育与收入之间的真实因果,消除虚假相关的可能性,并计算出相应的影响系数。发现和找出混沌因子,并将其以合适的统计方法予以隔离是开展量化研究、提升研究结果内部效度和外部效度的必要措施。
(3)对撞因子:X→Z3←Y。就目前的研究文献而言,对撞(colider)形式的变量关系是研究者很少关注的一类Z变量作用机制。它实际上是两条路径的结合:X→Z3和Y→Z3。例如,有才华→找女朋友←有容貌。在日常生活中,有才华的男孩子找到女朋友的概率比较大(正相关),同样,帅气的男孩子也比较容易受到女孩子待见(同样是正相关),但是在一般情况下,“有才华”和“帅气”并不存在相关关系(X与Y是独立的)。从变量控制角度,对撞因子的运作方式与中介因子和混沌因子正好相反,如将Z3变量控制起来,那不仅起不到“隔断”作用,反而会以“架桥”的方式使原本独立的X和Y产生关联。假如我们现在掌握了有女朋友群体的数据(换言之,我们只分析“找女朋友=1”的样本),那么我们将会看到“有才华”和“有容貌”之间出现了负相关,这种负相关可以解释为:发现某个男孩子没有容貌这一事实,会使我们更相信他富有才华。这种负相关被称为对撞偏倚或“辩解”效应(explain-away effect)。
简言之,在三种Z变量的基本类别中,混沌因子适合或需要采用控制变量方法,并借以实现研究者准确评估核心变量之间真实因果关系的目的;对撞因子则不适合,予以强行控制的结果是会造成虚假因果;而对中介因子的控制是否合适需要视具体情况而定,假如是完全中介,控制中介因子的后果是完全阻断X到Y的信息传递路径,导致两者不相关,而如果是部分中介,则可以通过控制中介因子评估X与Y的直接因果效应,如表2所示。

我们或可通过几个案例来展示假如控制变量不够规范(不经思索地控制所有变量)所造成的影响。
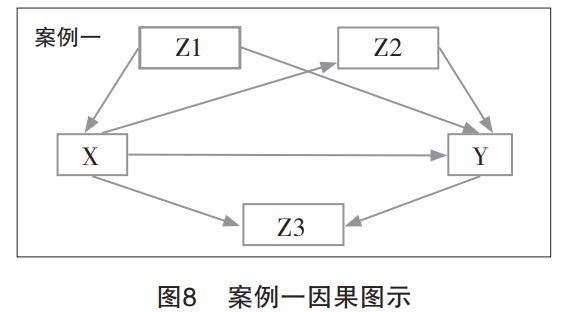
根据我们上文所做的界定,案例一(图8)实际上包含了三种第三方变量的作用类型,分别为:(1)X←Z1→Y的混沌因子作用机制;(2)X→Z2→Y的中介因子作用机制;(3)X→Z3←Y的对撞因子作用机制。正如上面所讲到的,如果我们不假思索地将Z1、Z2和Z3同时“控制”起来,那将对我们分析和评估核心变量X和Y的关系造成非常不好的影响。其一,Z1变量是混沌因子,控制Z1变量将会帮助研究者解决一部分混沌效应,有利于真实因果关系的发现,这是我们期望看到的结果;其二,Z2变量是中介因子,控制Z2变量可能有两种情况,即完全中介条件下的路径隔离和部分中介条件下的因果削弱,对控制该变量的效果要视具体情况而定;其三,Z3变量是对撞因子,控制Z3变量将引发灾难,人为架构起核心变量X与Y之间的关系桥梁,引发虚假关联。我们不妨找一个案例加以论证:X为教育,Y为收入,Z1为家庭资本,Z2为职业类型,Z3为慈善意愿。根据常识可以判断:“教育←家庭资本→收入”、“教育→职业类型→收入”和“教育→慈善意愿←收入”都是成立的。

与案例一相比,案例二(图9)看起来比较简化,只存在两种第三方变量的作用类型:(1)X←Z1→Y的混沌因子作用机制;(2)X→Z2←Z1的对撞因子作用机制。研究者可以通过控制Z1变量实现对混沌因子的阻断,准确估计X对Y的因果效应。但这里需要关注的是Z2变量,对撞因子Z2与核心变量X有关联,但与Y并没有直接联系,假如Z1变量和Z2变量皆可观测(可获得数据),那么是否控制Z2变量对模型结果不会产生任何影响:一方面,假设不控制Z2变量,对撞因子本身就会起到隔离作用;另一方面,假设控制Z2变量,那么人工构建的桥梁是核心变量X与混沌因子Z1之间的,而Z1变量已经被控制了,因此不会对核心变量Y具有实质性影响。复杂的地方在于,当Z1变量无法观测(数据缺失)时,一些研究者可能会将Z2变量作为Z1变量的替代变量(操作化)纳入模型中并控制起来,但这种做法只能部分消除混沌偏倚,并引入新的对撞偏倚。现实案例:X为教育,Y为收入,Z1为家庭资本,Z2为藏书量。
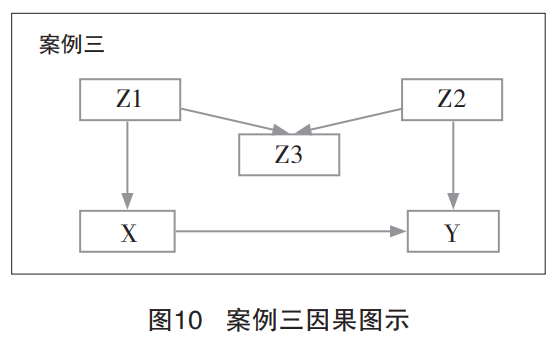
案例三(图10)所展示的是一种叫作“M偏倚”的偏倚类型。在这个案例中存在三个第三方变量的作用类型,分别为:(1)X←Z1→Z3的混沌因子作用机制;(2)Z3←Z2→Y的混沌因子作用机制;(3)Z1→Z3←Z2的对撞因子作用机制。在这个案例中,虽然Z1和Z2都是混沌因子,但是在该案例中我们其实不需要控制任何变量即可实现X到Y的第三方路径隔离。原因是对撞因子Z3的存在已经实现了对路径的隔断:X←Z1→Z3←Z2→Y。事实上,假如未对第三方变量的类型做深入思考的话,可能会得出“Z3变量是混沌因子”的结论。因为它既与核心变量X相关联(X←Z1→Z3),也与核心变量Y相关联(Z3←Z2→Y)。但假如我们真的控制了Z3变量,它才会真正成为“混沌因子”。理解M偏倚非常重要,因为它让我们意识到对第三方变量作用机制进行分类的重要意义,不能仅仅因为某个变量同时与核心变量X和Y都有影响就认为它是混沌因子而加以控制,方向也是重要的考量标准。例如,X为教育,Y为收入,Z1为家庭资本,Z2为关系网络,Z3为初职工作。
五、总结与讨论
无论是自然科学还是社会科学,研究者们在做的全部努力就是试图发现和总结事物背后的因果机制,但混沌因子的存在让这一过程变得更加艰难。自然科学家一般借助实验或准实验的方法实现对混沌因子的隔离,而受制于可操作性、变量关系复杂、研究伦理等诸多条件的限制,社会科学无法或很难借助实验方法开展相关研究,因此,使用统计隔离的方法貌似在实践上更为可行。其中,控制变量法以其成本低廉、操作方便的优势成为研究者最常使用的方法。本研究在文献回顾的基础上概括了控制变量方法的内在机制和先在假设,并基于对近十年发表于社会学权威杂志《社会学研究》上的149篇定量文献进行的相关分析,总结了社会学量化研究中控制变量方法使用的特征和问题。研究发现,其一,即使是在工具变量、倾向值匹配、双重差分等高阶统计控制方法引入之后,控制变量法仍是社会学量化研究者使用率最高的统计控制方法。其二,社会学定量研究在控制变量的使用中存在如下失范趋势,包括变量纳入的滥用化(越来越多)、变量选择的趋同化(越来越像)和变量分析的浅薄化(忽略内在关系)。定量研究总在被人诟病研究结论的一般性意义弱,同样的理论假设,使用不同的数据竟然得到截然相反的研究结论,甚至同样的数据,也可能因为变量纳入的顺序不同造成前后分析结论的云泥之别,控制变量方法的使用不规范可能是造成该结果的重要因素。
我们认为,对第三方变量作用机制的分析、总结和归类是规范控制变量方法使用的首要步骤。根据Z变量的作用机制我们可以总结出第三方Z变量的三种基本类型或形式,分别是:形式为X→Z1→Y的中介因子、形式为X←Z2→Y混沌因子和形式为X→Z3←Y对撞因子。在三种Z变量的基本类别中,混沌因子适合并需要采用控制变量方法,以实现研究者准确评估核心变量间真实因果关系的目的;对撞因子则不适合,强行控制的结果是造成虚假因果;而对中介因子的控制是否合适需要视具体情况而定,假如是完全中介,控制中介因子的后果是完全阻断X到Y的信息传递路径,导致两者不相关,而如果是部分中介,则可以通过控制中介因子评估X与Y的直接因果效应。不能仅仅因为某个变量同时与核心变量X和Y都有影响就认为它是混沌因子而加以控制,方向性是判定混沌因子的重要考量标准,控制中介因子和对撞因子可能不仅没有降低反而增加了模型的混沌效应。
无论如何,社会学量化研究者需要以谨慎的态度对待控制变量,不能不假思索地随意纳入控制变量,更不能把控制变量当作为了让数据结果更“漂亮”的工具。在使用控制变量时,研究者需要高标准、严要求选择变量,时刻警惕所选变量是否具备坚实的理论基础,通过分析变量的作用机制识别和筛选出合适的混沌因子并加以控制。关于如何推进控制变量使用的规范化,国内学者曹江雨等人给出的“控制变量应用决策树”可供参考。除此之外,在计算机和编程技术的推动下,计算社会科学范式逐步得到学术界认可,新型计算工具为社会科学研究者开展科学研究提供了丰富的手段和方法,如机器学习的机器选元和建模功能。发展到今天,机器学习技术在识别核心变量、剔除无关变量、筛选混沌因子、辨别工具变量等多个方面具有相当优势,并且机器学习建模甚至不需要过多考虑理论——体现为算法驱动。在传统最小二乘法(OLS)多元回归模型中,自变量、控制变量、中介变量等的选择主要仰仗于研究者的理论素养——体现为理论驱动,但是不可避免地总会引入一些与模型无关甚至增加模型复杂性的变量,降低模型解释力。基于正则化方法(regularization method)的机器学习自主建模技术则可以为研究者提供拟合效果更好的统计模型。和OLS模型相比,正则化模型在回归系数上加入了惩罚项(penalty term),可以通过引入偏差来减少方差和降低整体误差,从而提升模型的预测精度,代表方法如岭回归、Lasson回归等。
(注释与参考文献从略,全文详见中国人民大学复印报刊资料《社会学》2022年第3期/《深圳社会科学》2021年第6期)